반응형
경사하강법(Gradient Descent) :
- 손실 함수의 기울기(gradient)를 사용하여 모델의 가중치를 업데이트하는 최적화 알고리즘
- 가중치가 손실 함수의 값을 최소화하는 방향으로 이동시키는 것
- 기울기 계산 (Gradient Calculation): 손실 함수 L(θ)의 현재 가중치 θ에 대한 기울기 ∇L(θ)를 계산
- 가중치 업데이트 (Weight Update): 기울기에 학습률(learning rate) η을 곱한 값을 현재 가중치에서 뺀다.
- θ←θ−η∇L(θ)
- 업데이트된 가중치를 사용하여 다시 손실 함수의 기울기를 계산, 이 과정을 반복. 모델의 가중치는 점차 손실 함수를 최소화하는 방향으로 조정됨.학습률이 너무 크면 최적점에 도달하지 못하고 발산/진동 할 수 있으며, 너무 작으면 수렴 속도가 느려질 수 있다.
- η : learning rate 학습률, 기울기를 얼마나 크게 반영할지를 결정하는 하이퍼파라미터
Adagrad (Adaptive Gradient Algorithm)
Feature마다 중요도, 크기 등이 제각각이기 때문에 모든 Feature마다 동일한 학습률을 적용하는 것은 비효율적이다.
AdaGrad는 Feature별로 학습률(Learning rate)을 Adaptive하게,
각 파라미터마다 다른 learning rate을 적용하여, 학습 과정에서 학습률을 자동으로 조정
학습 초기에는 큰 학습률을 사용하고, 학습이 진행됨에 따라 학습률을 줄여 과적합을 방지하는 효과
1. 기울기 제곱의 누적합: 각 파라미터에 대해 과거 기울기의 제곱을 누적하여 학습률을 조정한다. 시간 t에서의 파라미터 x의 기울기 f_t-1에 대해 누적합 g_t는
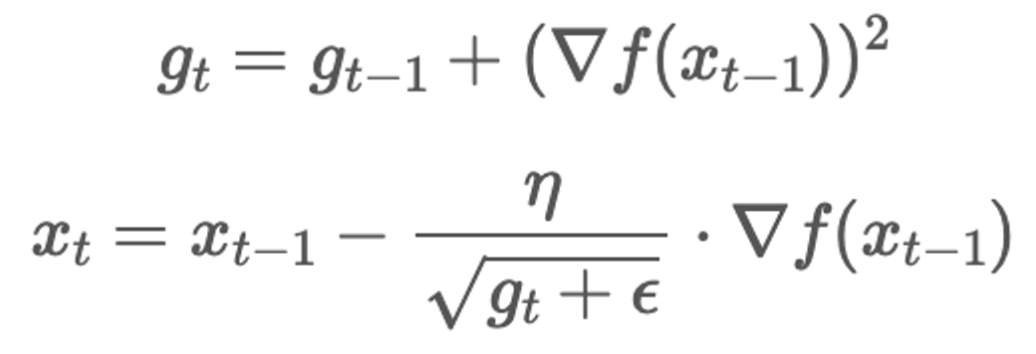
2. 학습률 조정: 각 파라미터마다 다른 학습률을 사용한다.
- ϵ : 수치적 안정성을 위해 추가되는 작은 값
- η : 초기 학습률을 나타내는 하이퍼파라미터
- 파라미터 업데이트 : 누적된 기울기 제곱합 g_t의 제곱근에 작은 상수 ϵ을 더한 값으로 학습률을 나누어 각 파라미터에 대해 학습률을 조정
장점:
- 적응형 학습률: 파라미터마다 다른 학습률을 사용하여 학습 초기에는 큰 학습률을 적용하고, 학습이 진행됨에 따라 학습률을 자동으로 줄인다.
- 효율적인 학습: 희소한 특징을 다루는 문제에서 자주 등장하지 않는 특징들에 대해 상대적으로 큰 학습률을 적용하여 효율적으로 학습할 수 있다.
단점:
- 학습률의 급격한 감소: 모든 기울기 제곱을 누적하기 때문에 학습이 진행될수록 학습률이 너무 작아질 수 있다.→ (g_t가 분모에 있기 때문) 학습이 지나치게 느려질 수 있다.
- 𝑔_𝑡 값이 점차 커지기 때문에 학습이 오래 진행되면 학습률(𝜂/𝑔𝑡+𝜖)이 0에 가까워져 더 이상 학습이 진행되지 않을 수 있다.
그래서 모델 학습에서 학습이 잘 이루어져 더 이상 변수의 값이 업데이트되지 않는 것인지, 𝑔𝑡 값이 지나치게 커져서 추가적으로 학습이 되지 않는 것인지 알기 어렵다.
--> 한계점을 개선한 최적화 기법: RMSProp
반응형
'AI > 최적화' 카테고리의 다른 글
| [최적화] (4) RMSProp (Root Mean Square Propagation) (0) | 2024.07.02 |
|---|---|
| [최적화] (3) 모멘텀과 SGD / Momentum 수학적 정의 / Adagrad와 차이 (2) | 2024.07.01 |