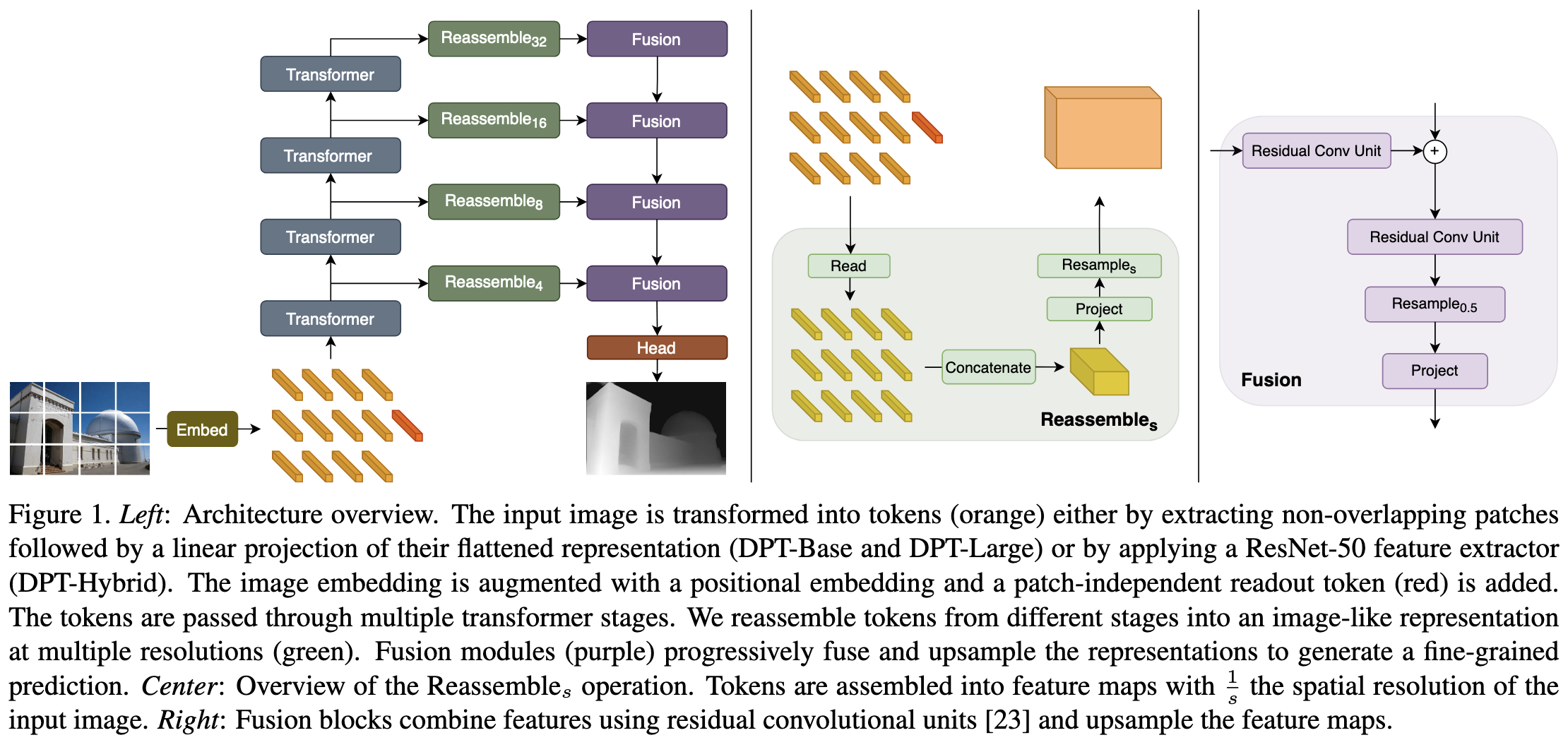
TMPI의 baseline model, adaptive depth plane placement ACM SIGGRAPH 2022 [Submitted on 24 May 2022]https://arxiv.org/abs/2205.11733 Single-View View Synthesis in the Wild with Learned Adaptive Multiplane ImagesThis paper deals with the challenging task of synthesizing novel views for in-the-wild photographs. Existing methods have shown promising results leveraging monocular depth estimation and ..