반응형
2020 ECCV
수정중
1. Introduction
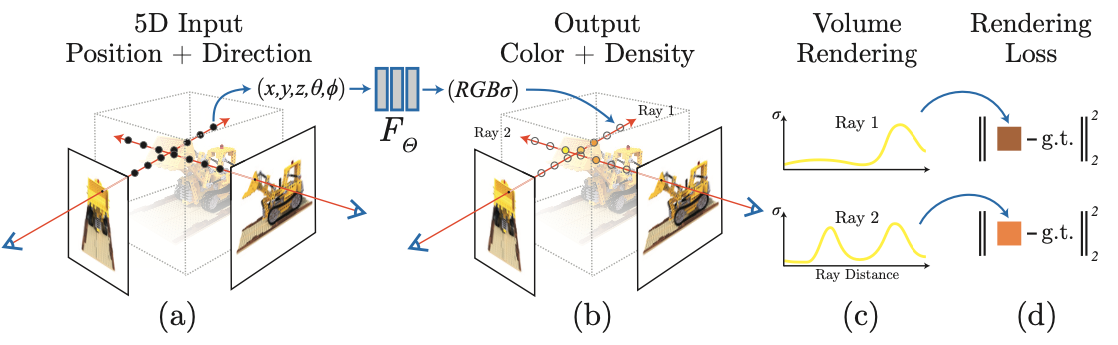
- 이 연구에서는 captured image set의 렌더링 에러를 최소화하기 위한, continuous 5D scene representation의 파라미터들을 최적화하는 novel view synthesis 방법을 다룬다.
- continuous 5D 함수로 표현 :
static scene을 공간의 각 방향 $(\theta, \phi)$, 각 지점 $(x, y ,z)$으로 방출되는 radiance를 출력하는 5D함수 - 각 포인트에서의 density : ray가 $(x, y ,z)$를 통과하면서 얼마나 많은 radiance가 축적되는지 컨트롤링하는 differential opacity(불투명함)같은 역할
- 이 방법은 convolutional layers 없는 deep fully-connected neural network를 최적화 (multilayer perceptron or MLP 라고함.)
-
single 5D coordinate (x,y,z,θ,φ) 에서 single volume density + view에 따라 달라지는 RGB color regressing하는 함수를 나타내도록 함.

NeRF를 특정 viewpoint에서 렌더링 하기 위해서 크게 다음 세 절차로 이루어진다.
- camera ray를 따라가 scene안에 넣어 샘플링된 3D points의 set을 생성한다.
- 이 Points로 대응되는 2D viewing direction을 신경망에 입력으로 넣고, color & density set들을 출력으로 생성
- 고전적인 volume rendering 기술을 사용해서 2D 이미지에 color & density 들을 축적
이 프로세스들은 naturally differentiable해서, 경사하강법을 사용할 수 있다.
그렇게 관찰된 이미지랑 렌더링된 대응되는 뷰 사이 오차를 최소화할 수 있게 되어서 최적화할 수 있다.
이것을 여러 뷰에서 이 오차들을 최소화하면 신경망이 일관성있게 모델 예측을 할 수 있게 된다.
-> 실제 underlying scene content가 포함된 위치에 대해 높은 density, 정확한 color들을 할당할 수 있게된다.
저자들은 NeRF의 basic구현이 complex scene에서 비효율적인 한계 발견
- high-resolution 표현으로 수렴되지 않음
- camera ray당 필요한 샘플 수가 비효율적
-> 해결법 :
- positional encoding으로 입력 5D 좌표(x,y,z,θ,φ)를 변환
- higher dimen- sional space로 변환하면서 MLP의 고주파 함수 표현이 가능 - hierachical sampling : 고주파 표현에 적합한 샘플 수로 줄여줌
- 중요한 콘텐츠에는 더 많은 sample 사용
- 덜 중요한 콘텐츠에는 적은 sample 사용
-> 복잡한 scene을 high-resolution으로 모델링할때 생기는 discretized voxel grid의 엄두도 못낼정도로 높은 저장비용<<을 극복.
Neural Radiance Field Scene Representation
반응형