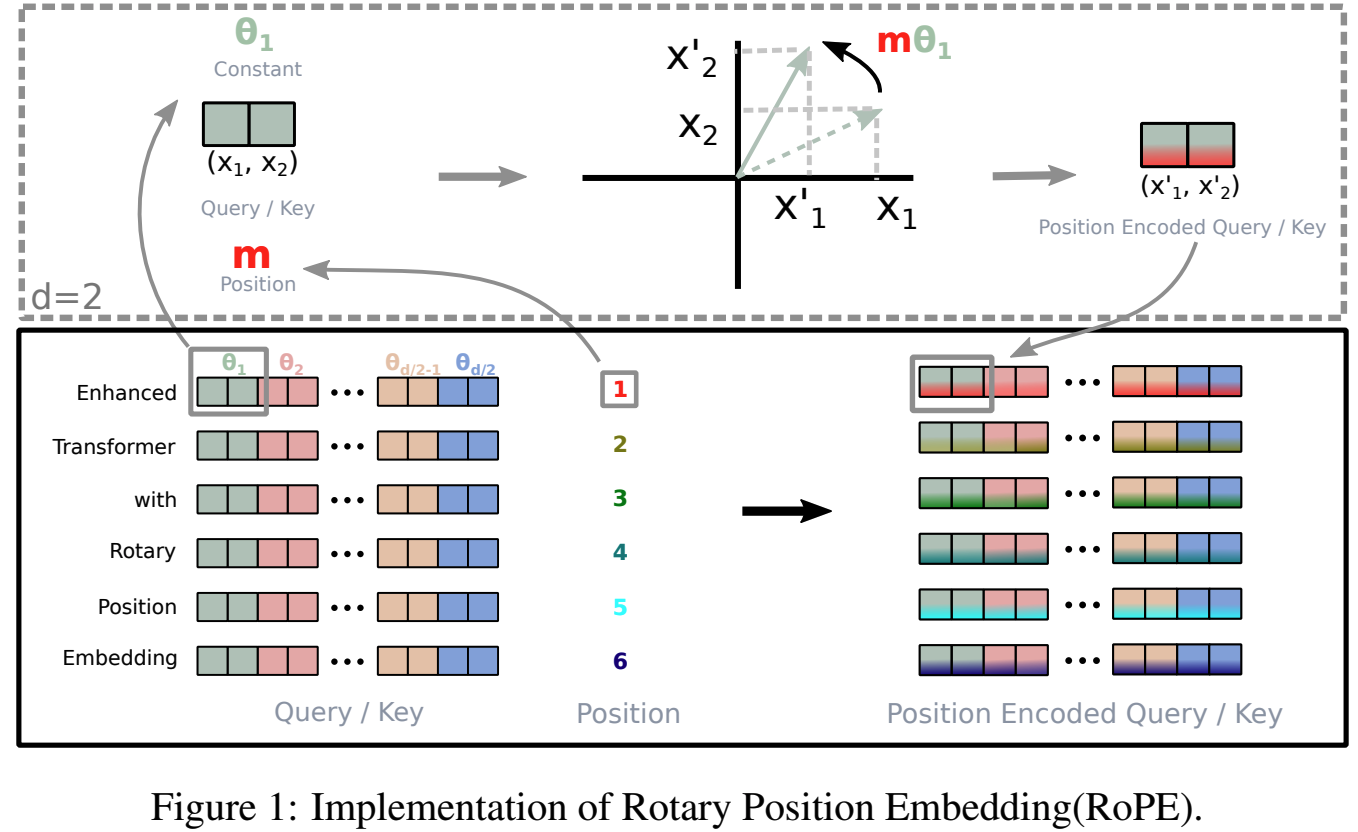
Transformer 구조(원래 NLP 분야에서 제안됨)는 현재 Computer Vision 영역에서도 SOTA 성능을 보이고 있다. 그러나 Vision Transformer(ViT)는 CNN과 달리 local processing이나 translation invariance와 같은 spatial inductive bias가 내장되어 있지 않다. 비전 영역에서 ViT는 이미지를 patch 단위로 분해하여 sequence로 처리하는데, 이 과정에서 원래의 2D 구조 정보가 사라진다. 따라서 Positional Encoding(PE)은 ViT가 이미지의 공간 정보를 학습하도록 만드는 핵심 요소이다.Positional Encoding의 중요성Self-attention은 순서를 고려하지 않는(permutation..