CVPR 2025
https://arxiv.org/pdf/2501.09898
https://nvlabs.github.io/FoundationStereo/
https://nvlabs.github.io/FoundationStereo/
Tremendous progress has been made in deep stereo matching to excel on benchmark datasets through per-domain fine-tuning. However, achieving strong zero-shot generalization — a hallmark of foundation models in other computer vision tasks — remains chall
nvlabs.github.io
https://github.com/NVlabs/FoundationStereo/
GitHub - NVlabs/FoundationStereo: [CVPR 2025 Oral] FoundationStereo: Zero-Shot Stereo Matching
[CVPR 2025 Oral] FoundationStereo: Zero-Shot Stereo Matching - NVlabs/FoundationStereo
github.com

0. Abstract
deep stereo matching 분야에서는 per-domain fine-tuning을 통해 benchmark dataset에서 우수한 성능을 내는 데에 큰 진전이 있었음.
하지만, 다른 computer vision task에서 foundation model의 특징으로 여겨지는 강력한 zero-shot generalization을 stereo matching에서 달성하는 것은 여전히 어려운 과제임.
본 논문에서는 이러한 문제를 해결하기 위해 FoundationStereo를 제안.
이 모델은 stereo depth estimation을 위한 foundation model로서, 강력한 zero-shot generalization을 달성하도록 설계됨.
이를 위해 먼저, 높은 다양성과 사실적인 시각 품질을 갖춘 100만 쌍의 synthetic stereo pair로 구성된 대규모 training dataset을 구축함.
이후, 애매한 샘플을 제거하기 위한 자동 self-curation 파이프라인을 적용
다음으로, 모델의 확장성을 높이기 위해 다양한 network architecture 구성 요소들을 설계
여기에는 sim-to-real gap을 줄이기 위해 vision foundation model에서 가져온 rich monocular prior를 적응시키는 side-tuning feature backbone, 그리고 효과적인 cost volume filtering을 위한 long-range context reasoning이 포함됨.
이러한 구성 요소들을 결합함으로써, 다양한 도메인에 걸쳐 높은 강건성과 정확도를 달성,
zero-shot stereo depth estimation에서 새로운 기준을 수립함.
- self-curation : 데이터를 스스로 골라내는 과정
- 100만 쌍이나 되는 synthetic stereo 이미지를 만들었지만,그 안에는 노이즈, 오류, 매칭이 잘 안 되는 쌍도 섞여있을 수 있음.
- 이걸 사람이 일일이 골라낼 수 없으니까, 모델이 자동으로 품질이 안 좋은 데이터 샘플을 제거하는 과정을 넣음.
- rich monocular prior : 단일 이미지 하나만 보고도 얻을 수 있는 깊이에 대한 풍부한 사전 지식
- side-tuning : 기존 backbone에 옆에 추가 모듈을 살짝 붙여 기능을 보완하는 방법을 의미함.
- 기존에 스테레오 매칭을 하던 backbone이 있는데, 여기에 rich monocular prior를 옆에서 주입하는 작은 네트워크를 덧붙여서 성능을 높이는 구조를 만듦.
- backbone 자체를 갈아엎지 않고, “side에서 살짝 도움을 주는” 방식이라 side-tuning이라 부름.
- cost volume : 스테레오 매칭에서 만들어지는 3D 구조, 이 픽셀이 어떤 시차(disparity)를 가질지 를 다양한 후보로 비교해 놓은 것임.
- 그런데 raw cost volume은 노이즈가 많고 엉성할 수 있음.
- 그래서 이걸 깨끗하고 정제된 형태로 만들어야 좋은 depth를 얻을 수 있음.
- cost volume filtering은 이 raw 데이터를 부드럽게 다듬고 정확하게 만드는 과정을 뜻함.
- 예시 : 초기에 rough하게 계산된 시차 후보들을, 주변 픽셀과 비교하고 smoothing해서 더 일관성 있는 시차 맵을 만들어냄.
- 스테레오 매칭할 때, 바로 주변 패치만 보는 게 아니라,
- 멀리 있는 비슷한 패턴이나 구조도 고려하면 매칭이 훨씬 정확해짐.
- long-range context reasoning
- 한 곳의 정보만 보는 게 아니라, 멀리 떨어진 다른 부분까지 참고해서 판단하는 것을 의미함.
- 이를 위해 transformer 기반 long-range attention 같은 구조를 씀.
- 예시 : 초기에 rough하게 계산된 시차 후보들을, 주변 픽셀과 비교하고 smoothing해서 더 일관성 있는 시차 맵을 만들어냄.
1. Introduction
최초의 stereo matching 알고리즘이 등장한 지 거의 반세기가 지난 지금, 우리는 큰 발전을 이루었음.
최근의 stereo 알고리즘들은 training datasets 의 급증proliferation과 deep neural network architectures의 발전 덕분에 가장 어려운 benchmark에서도 거의 포화 수준의 성능을 달성함.
그럼에도 불구하고, 목표 도메인에 맞춘 dataset으로의 fine-tuning은 여전히 경쟁력 있는 결과를 얻기 위한 기본적인 방법으로 사용되고 있음.
scaling law [32, 46, 78, 79]를 통해 computer vision의 다른 문제들에서는 zero-shot generalization이 가능하다는 것이 증명되었지만, stereo matching 알고리즘은 왜 그와 같은 수준의 일반화를 달성하지 못하는가?
- Scaling Law : 모델의 크기(size), 데이터 양, 계산량을 늘리면,→ 성능(performance)이 일정한 패턴으로 좋아진다 는 법칙을 의미함.
- 초거대 모델 시대에 등장한 개념, 특히 GPT, CLIP, DINO, Flamingo 같은 모델들이 scaling law를 잘 따름.
- 즉, 모델이 커지면 제로샷(Zero-shot) 성능도 자연스럽게 올라가는 경향이 있음.
- classification, detection, segmentation 같은 CV task들은 scaling law 덕분에 모델 크기 키우고 데이터 늘리면 제로샷도 자연스럽게 잘됨.
- 그런데 stereo matching은 그렇지가 않음. → scaling law를 따른다고 무조건 잘 안 됨.
- 왜 stereo matching은 scaling law처럼 generalization이 안 될까?
- 1. 구조적인 문제가 다름
- • classification은 global semantics (ex. 이 사진은 고양이인가?)를 학습
- • stereo matching은 pixel-level 정밀 alignment (ex. 이 픽셀이 어디로 이동했나?)를 학습
pixel-level 문제는 global noise에 훨씬 민감하고, scale-up만으로 해결이 안 됨.
- 2. label noise에 극도로 민감함
- • stereo matching은 레이블(=disparity)이 조금만 틀려도 성능이 확 무너짐
• 반면 classification은 약간 noisy label이 있어도 robust함
➡️ scaling law는 noise가 어느정도 커버 가능할 때만 잘 작동함. - 3. sim-to-real gap이 심함
• stereo matching은 synthetic data(합성 이미지)로 학습해도, 실제 환경(real world)로 넘어가면 성능이 급격히 나빠짐
• light 변화, texture, camera calibration 차이 등이 심각하게 영향을 줌
➡️ vision task 중에서도 stereo matching은 sim-to-real gap이 특히 심함.
- unary feature :한 장의 이미지 안에서 각 픽셀에 대해 뽑은 기본적인 feature를 의미
- left feature와 right feature 각각을 unary feature라고 부름
- cost란 : 두 이미지 사이의 “matching degree” (얼마나 잘 맞는지) 를 나타내는 값을 의미
- stereo에서는 left 이미지의 픽셀과 right 이미지의 여러 후보 픽셀을 비교해야 함.
이때 각 후보마다 비용(cost) 을 계산, 잘 맞으면 cost가 작음 • 안 맞으면 cost가 큼 - left image의 (x, y) 픽셀과 • right image의 (x - d, y) 픽셀 (여러 시차 d 후보들)을 비교
similarity (or distance)를 계산해서 cost로 저장함 ➡️ 이걸 cost volume이라는 3차원 구조로 쌓음. (크기: [B, D, H, W], D는 disparity 후보 수)
- stereo에서는 left 이미지의 픽셀과 right 이미지의 여러 후보 픽셀을 비교해야 함.
대표적인 stereo 네트워크들 [11, 41, 53, 54, 73, 80]은 unary feature로부터 cost volume을 구성하고, 3D CNN을 사용하여 cost를 필터링함.
Refinement 기반 방법들 [14, 21, 27, 34, 36, 60, 67, 86]은 GRU와 같은 recurrent 모듈을 기반으로 disparity map을 반복적으로 정제함.
이러한 방식은 per-domain fine-tuning 환경에서는 public benchmark에서 성공적인 성능을 보이지만, 더 큰 dataset에 대해 확장하려면 비국소 정보를 모으는 데에 어려움을 겪음.
다른 방법들 [35, 68]은 unary feature 추출에 transformer 구조를 도입했지만, cost volume이나 iterative refinement 같은 특화 구조가 부족하여 높은 정확도를 달성하지 못함.
이러한 한계들은 stereo 네트워크가 다른 도메인으로 잘 일반화되는 모델로 발전하는 데에 제약이 되어왔음.
물론 cross-domain generalization을 시도한 일부 연구들이 존재하긴 했으나 [10, 17, 37, 49, 82, 84], 이들은 네트워크 구조의 부족한 설계, 혹은 부족한 training data 혹은 그 둘 모두로 인해, 목표 도메인에서 fine-tuning한 모델에 비해 경쟁력 있는 성능을 내지 못함.
이들 대부분은 Scene Flow [43]처럼 비교적 작은 규모(4만 쌍의 annotation된 이미지 페어)의 dataset만을 이용해 실험되었음.
결과적으로, 이들 방법은 즉시 사용 가능한(off-the-shelf) 솔루션이 되지 못하며, 이는 다른 task에서 나타나는 vision foundation model의 뛰어난 일반화 능력과 대조됨.
이러한 한계를 해결하기 위해, 우리는 FoundationStereo를 제안함.
이 모델은 per-domain fine-tuning 없이도 강력한 zero-shot generalization을 달성하는 stereo depth estimation을 위한 대형 foundation model임.
우리는 다양성과 사실성이 높은 100만 쌍의 synthetic stereo image pair로 구성된 대규모 고품질 training dataset을 통해 네트워크를 학습함.
도메인 무작위화된 synthetic 데이터 생성 과정에서 필연적으로 생성되는 애매한 샘플들을 제거하기 위한 자동 self-curation 파이프라인도 함께 개발함.
sim-to-real 간의 차이를 줄이기 위해, 실제 monocular 이미지 기반으로 학습된 DepthAnythingV2 [79]에서 가져온 rich prior를 stereo setup에 맞게 적응시키는 side-tuning feature backbone을 제안함.
이러한 rich monocular prior가 4D cost volume에 내재되어 있을 때 효과적으로 활용하기 위해, 우리는 Attentive Hybrid Cost Volume (AHCF) 모듈을 제안함.
이 모듈은 다음 두 가지로 구성됨:
- 3D Axial-Planar Convolution (APC): 일반적인 3D convolution을 공간(spatial)과 disparity 축으로 분리된 두 개의 3D convolution으로 나눠 receptive field를 확장하고 feature aggregation을 향상시킴
- Disparity Transformer (DT): cost volume 내의 disparity 공간 전체에 대해 self-attention을 수행하여 전역적인 맥락 추론이 가능하도록 함
receptive field란?
- CNN을 여러 방향(또는 축)으로 나눠서 적용하면, 한 번에 더 넓은 영역을 볼 수 있게 만들고,
멀리 떨어진 feature들도 잘 모을 수 있다는 뜻임.
- 한 픽셀이 얼마나 넓은 입력 영역을 보고 있는지를 나타냄.
- receptive field가 크면 더 넓은 문맥(context) 정보를 알 수 있음.
- EX) 일반 3×3 convolution은 주변 9픽셀만 봄. 그런데,
- x축(가로)으로 1D convolution
- y축(세로)으로 1D convolution
- disparity축(D축)으로 1D convolution
- → 이런 식으로 분리해서 적용하면, receptive field가 각각 방향으로 엄청 커짐.
- 결국, 멀리 떨어진 정보를 더 잘 모아서 feature를 풍부하게 만드는 것을 의미함.
DT 방식?
- cost volume 안의 disparity 방향(D축) 전체를 한 번에 self-attention으로 연결해서,
“가까운 물체”와 “먼 물체” 간의 관계까지 한꺼번에 파악할 수 있게 한다는 뜻임. - 기존 방식 문제점
- 3D CNN은 local (작은 윈도우)만 보고 처리함.
- 그래서 멀리 떨어진 disparity 후보들 간 연관성을 잘 못 앎.
- 모든 disparity 후보를 self-attention으로 연결함, 멀리 있는 깊이 후보끼리도 맥락을 잡아주는 것이 DT의 핵심임.
- 예를 들면,
- disparity 5와 disparity 20 사이에 강한 관계가 있을 수도 있는데, 이걸 transformer로 직접 연결해서 학습함.
예시
- 가까운 거리(시차 5) 물체와 먼 거리(시차 20) 배경이 서로 연관되어 있을 때, 단순 CNN은 이걸 잘 모르지만,
Transformer는 attention을 통해 멀리 있는 것끼리도 직접 연결하고 reasoning할 수 있음. - 이러한 구성 요소들은 모델 표현력을 크게 향상시키며, 더 나은 disparity 초기화와 후속 iterative refinement를 위한 강력한 feature를 가능하게 함.
이러한 구성 요소들은 모델 표현력을 크게 향상시키며, 더 나은 disparity 초기화와 후속 iterative refinement를 위한 강력한 feature를 가능하게 함.
- disparity 초기화 : stereo pair를 처음 입력받았을 때, 처음 대충 시차(disparity)를 예측하는 것
- 두 이미지(left, right)를 보고, cost volume을 통해 각 픽셀이 어느 정도 shift될지를 대략적으로 먼저 추정하는 단계임.
- 이건 빠르고 거친 rough prediction임. 정확할 필요는 없지만, 어느 정도 “맞는 방향”이어야 이후 refinement가 쉬워짐.
- ex) 처음에 (x, y) 픽셀이 disparity=10 정도 될 것 같다고 예측함.
완전히 맞진 않아도, 5~15 정도 사이에서만 맞으면 괜찮음. 이걸 disparity 초기화라고 부름.
- iterative refinement : 처음 대충 예측한 disparity를 점점 더 정확하게 여러 번에 걸쳐 수정하는 것
- 초기화된 disparity가 조금 부정확할 수 있음. 그래서 모델이 이걸 반복(iterative)하면서 refinement(수정) 함.
- 각 refinement 스텝마다 disparity를 조금씩 보정하고 더 정확하게 맞춤.
Our contributions can be summarized as follows :
- FoundationStereo라는 zero-shot generalization이 가능한 stereo matching 모델을 제안함. 이 모델은 target domain에서 fine-tuning한 기존 연구들과 비슷하거나 더 나은 성능을 보이며, in-the-wild 데이터에 대해서도 기존 방법들을 크게 능가함.
- 다양성과 사실성이 높은 100만 개의 synthetic stereo pair로 구성된 대규모 고품질 dataset을 구축하고, 품질이 낮은 샘플을 자동으로 제거하는 self-curation 파이프라인을 개발함.
- 인터넷 규모의 rich semantic 및 geometric prior를 활용하기 위해, ViT 기반 monocular depth estimation 모델 [79](Depth anything v2.)을 stereo 구조에 적응시키는 **Side-Tuning Adapter (STA)**를 제안함.
- **3D Axial-Planar Convolution (APC)**이 포함된 hourglass 모듈과 Disparity Transformer (DT) 모듈로 구성된 **Attentive Hybrid Cost Filtering (AHCF)**을 개발함. DT는 disparity 차원에서 full self-attention을 수행함.
2. 관련 연구 (Related Work)
Deep Stereo Matching
최근 stereo matching의 발전은 deep learning에 의해 촉진되었으며, 정확도와 일반화 성능이 크게 향상됨.
Cost volume aggregation 방식은 unary feature로부터 cost volume을 구성하고, 3D CNN을 사용하여 volume filtering을 수행함 [11, 41, 53, 54, 73, 80].
하지만, 이러한 방식은 높은 메모리 사용량으로 인해 고해상도 이미지에 직접 적용하기 어려움.
Iterative refinement 방식은 RAFT [57]에서 영감을 받아, 비용이 큰 4D volume 구성과 filtering 단계를 생략하고 disparity를 반복적으로 정제함 [14, 21, 27, 34, 36, 60, 67, 86].
이러한 방법은 다양한 disparity 범위에 대해 잘 일반화되지만, 반복적인 업데이트는 시간이 오래 걸리고 long-range context reasoning이 부족함.
최근 연구들 [71, 72]은 cost filtering과 iterative refinement의 장점을 결합함.
Vision transformer의 발전에 따라, 또 다른 연구 방향 [23, 35, 68]에서는 transformer 구조를 stereo matching에 도입, 특히 unary feature 추출 단계에서 활용함.
하지만 이들 역시 per-domain fine-tuning에서는 성공을 거두었으나, zero-shot generalization에서는 여전히 도전적인 문제로 남아 있음.
이 문제를 해결하기 위해 [10, 17, 37, 49, 82, 84]는 cross-domain generalization을 위해 domain-invariant feature 학습을 시도함.
이들은 주로 Scene Flow [43] 데이터셋을 사용하여 학습함.
최근 병행된 연구 [3]는 monocular prior를 강화한 correlation volume을 통해 놀라운 zero-shot generalization 성능을 달성함.
그러나, scaling law에 의해 뒷받침되는 vision foundation model의 강력한 일반화 능력은 stereo matching 분야에서 아직까지 현실적인 응용으로 완전히 구현되지는 못함.
Stereo Matching Training Data
deep learning 모델 학습에서 training data는 필수적임.
KITTI 12 [20]와 KITTI 15 [45]는 주행 시나리오에 대한 수백 개의 training pair를 제공함.
DrivingStereo [76]는 이를 18만 쌍으로 확장함.
하지만, LiDAR 센서로 얻은 sparse ground-truth disparity는 정확하고 조밀한 stereo matching 학습에 한계를 줌.
Middlebury [51]와 ETH3D [52]는 주행 외에도 실내외 장면을 포함하되, training 데이터 수는 적음.
Booster [48]는 투명한 객체에 중점을 둔 real-world dataset을 제안함.
InStereo2K [2]는 structured light system을 통해 보다 조밀한 ground-truth disparity를 갖는 2,000쌍의 stereo pair로 구성됨.
하지만 데이터 크기의 부족, ground-truth의 불완전함, 실세계에서의 수집 한계 등으로 인해, synthetic 데이터를 학습에 사용하는 추세가 확산됨.
대표적인 예로는 다음이 있음:
Scene Flow [43], Sintel [6], CREStereo [34], IRS [64], TartanAir [66], FallingThings [61], Virtual KITTI 2 [7], CARLA HR-VS [75], Dynamic Replica [28].
Table 1에서는 제안한 **FoundationStereo Dataset (FSD)**를 기존 stereo matching용 synthetic dataset들과 비교함.
우리의 dataset은 다양한 시나리오를 포괄하며, 현재까지 가장 큰 데이터 볼륨을 자랑함.
또한 다양한 3D asset을 포함하고, 랜덤화된 카메라 파라미터 하에서 stereo 이미지를 생성, 렌더링 및 공간 배치에서 높은 사실감을 달성함.

Vision Foundation Models
Vision foundation model은 2D, 3D, multi-modal 정렬을 포함한 다양한 vision task에서 큰 발전을 이룸.
CLIP [47]은 대규모 이미지-텍스트 쌍을 학습하여 시각적 모달리티와 텍스트 모달리티를 정렬시킴. 이를 통해 zero-shot classification과 cross-modal task를 가능케 함.
DINO 시리즈 [8, 38, 46]는 self-supervised 학습을 통해 dense representation을 학습하고, segmentation 및 recognition task에 중요한 정밀 feature를 효과적으로 포착함.
SAM 시리즈 [32, 50, 77]는 point, bounding box, language 등 다양한 프롬프트에 기반한 segmentation에서 높은 범용성을 보여줌.
유사한 발전은 3D vision task에서도 나타남.
DUSt3R [65]와 MASt3R [33]는 보정되지 않은 카메라와 자세 정보 없이도 dense 3D reconstruction을 수행할 수 있는 일반화된 framework를 제안함.
FoundationPose [69]는 새로운 객체에 대한 6D pose estimation 및 tracking을 위한 통합 framework를 제안함.
본 논문과 더 밀접한 연구로는, monocular depth estimation과 multi-view stereo에서 강력한 일반화 성능을 보인 연구들이 있음 [4, 29, 78, 79, 26].
이러한 접근들은 scaling law 하에서 foundation model이 per-domain fine-tuning 없이도 다양한 시나리오에서 강건한 응용을 지원하는 방향으로 발전하고 있음을 보여줌.

3. Approach
전체 네트워크 아키텍처는 Fig. 2에 제시됨. 이 섹션에서는 각 구성 요소를 설명함.
3.1. Monocular Foundation Model Adaptation
stereo 네트워크가 주로 synthetic dataset으로 학습되었을 때 발생하는 sim-to-real gap을 줄이기 위해, 인터넷 규모의 real data로 학습된 최근의 monocular depth estimation 성과 [5, 79]를 활용함.
Depth Pro: Sharp monocular metric depth in less than a second.
Depth anything v2. In Proceedings of Neural Information Processing Systems (NeurIPS)
ViT 기반 monocular depth estimation 네트워크를 stereo 환경에 맞게 적응시키기 위해 CNN 네트워크를 사용하며, 이로써 CNN과 ViT 구조의 강점을 결합함.
CNN과 ViT를 결합하기 위한 다양한 설계 선택지를 탐색했으며, 이는 Fig. 3 (left)에 정리되어 있음.
(a)는 frozen된 DepthAnythingV2 [79]의 DPT head에서 나온 feature pyramid만을 사용하고 CNN feature는 사용하지 않음.
(b)는 ViT-Adapter [12]와 유사하게 CNN과 ViT 간 feature를 교환함.
(c)는 DepthAnythingV2의 최종 출력 head 전에 4×4 stride 4 convolution을 적용하여 feature를 downscale하고, 이 feature를 같은 단계의 CNN feature와 concat하여 1/4 scale의 hybrid feature를 생성함.
이때 side CNN 네트워크는 ViT feature를 stereo matching task에 적응시키도록 학습됨 [83].
놀랍게도, 단순함에도 불구하고 (c) 방식이 stereo matching task에서 다른 대안들보다 훨씬 우수한 성능을 보였으며, 이는 실험 결과(Sec. 4.5)에서 확인됨. 따라서 (c)를 STA Side-Tuning Adapter모듈의 주된 설계로 채택함.
형식적으로, 좌우 이미지 쌍 \(I_l, I_r \in \mathbb{R}^{H \times W \times 3}\)가 주어졌을 때, STA 내부의 CNN 모듈로는 EdgeNeXt-S [40]를 사용하여 multi-level pyramid feature를 추출함.
1/4 단계 feature에는 DepthAnythingV2의 feature가 포함됨:
\(f^{(i)}_l, f^{(i)}_r \in \mathbb{R}^{C_i \times H_i \times W_i}, i \in \{4, 8, 16, 32\}\)
EdgeNeXt-S는 메모리 효율성과 더 큰 CNN backbone들이 추가적인 이점을 제공하지 않았기 때문에 선택됨.
DepthAnythingV2에 이미지를 입력할 때는, pretrained patch size와 일치시키기 위해 먼저 이미지를 14로 나눠지는 크기로 resize함.
STA의 weight는 I_l, I_r에 동일하게 공유됨.
유사하게, context feature 추출에도 STA를 사용함.
단, CNN 모듈은 residual block [25]과 down-sampling layer로 구성되어 있음.
이로부터 여러 scale의 context feature \(f^{(i)}_c \in \mathbb{R}^{C_i \times H_i \times W_i}, i \in \{4, 8, 16\}\)가 생성됨 [36].
f_c는 ConvGRU block의 hidden state 초기화와 매 iteration마다의 입력으로 사용되어, 점진적으로 정제되는 context 정보를 기반으로 iterative 과정을 효과적으로 유도함.
Fig. 3은 rich한 monocular prior가 epipolar line을 따라 naive한 correspondence search로는 처리하기 어려운 애매한 영역에서도 신뢰도 높은 예측을 가능케 하는 힘을 시각적으로 보여줌.
DepthAnythingV2의 scale ambiguity가 있는 raw monocular depth를 직접 사용하는 대신, stereo 이미지 양쪽에서 추출한 latent feature를 geometric prior로 활용하고, 이후 cost filtering을 통해 비교함.
다음 단계에서 이에 대해 설명함.

3.2. Attentive Hybrid Cost Filtering
Hybrid Cost Volume Construction.
이전 단계에서 추출된 1/4 스케일의 unary feature \(f^4_l, f^4_r\)를 바탕으로, 다음과 같이 group-wise correlation과 concatenation을 조합하여 cost volume \(V_C \in \mathbb{R}^{C \times D/4 \times H/4 \times W/4}\)을 구성함 [24]:
\(\begin{aligned} &V_{\text{gwc}}(g, d, h, w) = \langle \hat{f}^{(4)}{l,g}(h, w), \hat{f}^{(4)}{r,g}(h, w - d) \rangle \\ &V_{\text{cat}}(d, h, w) = \left[ \text{Conv}(f^{(4)}l)(h, w), \text{Conv}(f^{(4)}r)(h, w - d) \right] \\ &V_C(d, h, w) = \left[ V{\text{gwc}}(d, h, w), V{\text{cat}}(d, h, w) \right] \end{aligned}\)
여기서 \hat{f}는 학습 안정성을 위한 L2 정규화 feature를 의미하며, ⟨·, ·⟩는 내적을 나타냄.
\(g \in \{1, 2, …, G\}\) 는 총 G = 8개의 feature group 중 하나이며, 전체 feature를 균등하게 나눈 것임.
d \in \{1, 2, …, D/4\}는 disparity index를 의미함.
[·, ·]는 channel 방향의 concatenation임.
- Vgwc는 기존 correlation 기반 정합 비용의 장점을 활용하며, 각 group에서 다양한 유사도 측정 feature를 제공함.
- Vcat는 좌우 feature를 shifted disparity로 concat함으로써 rich monocular prior를 포함한 unary feature를 유지함.
메모리 사용량을 줄이기 위해, concatenation 전에 kernel size 1의 convolution으로 unary feature의 dimension을 14로 줄임 (이때 \(f^4_l과 f^4_r\)에 같은 weight를 사용함).
다음으로는 cost volume filtering을 위한 두 개의 하위 모듈을 설명함.
Axial-Planar Convolution (APC) Filtering.
3개의 downsampling 블록과 3개의 upsampling 블록으로 구성된 3D convolution 기반 hourglass 네트워크를 사용하여 cost volume을 filtering함 [1, 71].
작은 disparity 크기에는 일반적으로 3×3×3의 3D convolution을 사용함 [9, 24, 71].
하지만 고해상도 이미지에서 큰 disparity를 다루려 할 때는 3D convolution이 문제를 일으킴.
이는 disparity 축이 초기 disparity 분포를 모델링해야 하기 때문임.
단순히 kernel size를 키우는 것은 메모리 사용량 증가로 인해 실용적이지 않음.
예: 5×5×5 kernel을 사용할 경우 80GB GPU에서도 메모리 부족이 발생함.
이는 대용량 데이터 학습 시 모델의 표현력을 심각하게 제한함.
이를 해결하기 위해, 우리는 Axial-Planar Convolution을 제안함.
기존의 3×3×3 convolution을 다음의 두 개로 분해함:
- 공간 방향 convolution: \(K_s \times K_s \times 1\)
- disparity 방향 convolution: \(1 \times 1 \times K_d\)
각 convolution 뒤에는 BatchNorm과 ReLU가 따라옴.
APC는 3D 버전의 Separable Convolution [16]으로 간주될 수 있으나, 채널을 group으로 나누지 않고 spatial과 disparity만 분리하는 점이 다름.
이는 cost volume에서 disparity 차원이 feature 비교 정보를 특별히 인코딩하기 때문임.
APC는 hourglass 네트워크의 downsampling 및 upsampling layer를 제외한 가능한 모든 부분에 적용됨.
Disparity Transformer (DT).
이전 연구들 [35, 68]은 transformer 구조를 unary feature 추출에 도입하여 stereo 학습의 확장을 시도했으나, cost filtering 과정은 간과되어 왔음.
cost filtering은 correspondence 정보를 포함하는 핵심 단계이며, 정확한 stereo matching을 위해 중요함.
이에 따라, 우리는 4D cost volume에서 long-range context reasoning을 향상시키기 위해 **Disparity Transformer (DT)**를 도입함.
앞서 Eq. (1)로부터 얻은 V_C에 대해, 먼저 kernel size 4×4×4, stride 4인 3D convolution을 적용하여 cost volume을 downsize함.
그 후 이 volume을 disparity 길이를 가진 token sequence 배치로 reshape함.
position encoding을 적용한 후, 4개의 transformer encoder 블록에 입력함.
이때 **FlashAttention [18]**을 사용하여 multi-head self-attention [63]을 수행함.
과정은 다음과 같이 표현됨:
\(\begin{aligned} Q_0 &= \text{PE}(R(\text{Conv}_{4×4×4}(V_C))) \in \mathbb{R}^{(H/16 \cdot W/16) \times C \times D/16} \\ \text{MultiHead}(Q,K,V) &= [\text{head}_1, …, \text{head}_h] W_O \\ \text{head}_i &= \text{FlashAttention}(Q_i, K_i, V_i) \\ Q_1 &= \text{Norm}(\text{MultiHead}(Q_0, Q_0, Q_0) + Q_0) \\ Q_2 &= \text{Norm}(\text{FFN}(Q_1) + Q_1) \end{aligned}\)
여기서 R(·)은 reshape 연산, \text{PE}(·)는 position encoding, [·, ·]는 channel 방향의 concat, W_O는 linear weight를 의미함.
head 수는 h = 4임.
최종적으로, DT의 출력은 trilinear interpolation을 통해 V_C와 같은 크기로 upsample되며, Fig. 2에서처럼 hourglass 출력과 더해짐.

Initial Disparity Prediction.
filtered cost volume V{\prime}_C에 soft-argmin [30]을 적용하여 초기 disparity d_0를 예측함:
\(d_0 = \sum_{d=0}^{D/4 - 1} d \cdot \text{Softmax}(V{\prime}_C)(d)\)
여기서 d_0는 원본 이미지 해상도의 1/4 스케일로 표현된 disparity임.
3.3. Iterative Refinement
초기 disparity d_0가 주어지면, 이를 점진적으로 정제하기 위해 iterative GRU 업데이트를 수행함. 이는 local optimum을 피하고 수렴 속도를 빠르게 해줌 [71]. 일반적으로, k번째 업데이트는 다음과 같이 정의됨:
\(\begin{aligned} &V_{\text{corr}}(w{\prime}, h, w) = \langle f_l^{(4)}(h, w), f_r^{(4)}(h, w{\prime}) \rangle \\ &F_V(h, w) = [V{\prime}C(d_k, h, w), V{\text{corr}}(w - d_k, h, w)] \\ &x_k = [\text{Conv}_v(F_V), \text{Conv}d(d_k), d_k, c] \\ &z_k = \sigma(\text{Conv}z([h{k-1}, x_k])) \\ &r_k = \sigma(\text{Conv}r([h{k-1}, x_k])) \\ &\hat{h}k = \tanh(\text{Conv}h([r_k \odot h{k-1}, x_k])) \\ &h_k = (1 - z_k) \odot h{k-1} + z_k \odot \hat{h}k \\ &d{k+1} = d_k + \text{Conv}\Delta(h_k) \end{aligned}\)
여기서 ⊙는 element-wise 곱, \sigma는 sigmoid 함수임.
\(V_{\text{corr}} \in \mathbb{R}^{W/4 \times H/4 \times W/4}\)는 pairwise correlation volume을 의미함.
F_V는 현재 disparity d_k에 기반하여 lookup된 volume feature임.
\(c = \text{ReLU}(f_c)\)는 좌측 이미지로부터 얻은 context feature를 나타내며, Sec. 3.1에서 언급된 STA 기반 feature가 포함됨. 이 feature는 rich monocular prior를 활용하여 refinement 과정을 효과적으로 안내함.
총 세 개의 GRU block을 사용하여 coarse-to-fine 방식으로 hidden state를 업데이트함.
초기 hidden state는 context feature로부터 다음과 같이 생성됨: \(h_0^{(i)} = \tanh(f_c^{(i)}), i \in \{4, 8, 16\}.\)
각 단계에서는 attention 기반 selection 메커니즘 [67]을 활용하여 서로 다른 주파수의 정보를 포착함.
최종적으로, d_k는 convex sampling [57]을 통해 full resolution으로 upsample됨.
3.4. Loss Function
모델은 다음의 목적 함수를 사용하여 학습됨:
\(\mathcal{L} = |d_0 - \bar{d}|{\text{smooth}} + \sum{k=1}^{K} \gamma^{K - k} \| d_k - \bar{d} \|_1\)
여기서\(\bar{d}\)는 ground-truth disparity임.
\(|\cdot|_{\text{smooth}}\)는 smooth L1 loss를 의미하고, k는 반복 횟수, \(\gamma\)는 0.9로 설정됨.
반복 refinement된 disparity에 대해 지수를 증가시키는 가중치를 적용함 [36].
3.5. Synthetic Training Dataset
우리는 NVIDIA Omniverse를 이용해 대규모 synthetic training dataset을 생성함.
이 **FoundationStereo Dataset (FSD)**는 반사, 낮은 텍스처, 심한 가림 현상 등 stereo matching의 핵심 문제들을 포함함.
dataset의 다양성을 확장하기 위해 domain randomization [58]을 수행함.
무작위 stereo baseline, 초점 거리, 카메라 시점, 조명 조건, 객체 배치를 포함함.
한편, 고해상도의 텍스처와 path-tracing 기반의 고품질 렌더링을 위해 다양한 3D asset을 활용함.
Fig. 4는 structured indoor/outdoor 장면과 함께 다양한 기하 구조 및 텍스처를 가진 flying object가 복잡하지만 사실적인 조명 환경 하에서 등장하는 샘플을 보여줌.
자세한 내용은 appendix에 포함됨.

Iterative Self-Curation.
이론적으로 synthetic data는 무제한 생성이 가능하고, randomization을 통해 높은 다양성 확보가 가능함.
하지만 구조화되지 않은 flying object 장면에서는 불가피하게 애매한 샘플이 생성되어 학습을 방해함.
이를 제거하기 위해 자동 iterative self-curation 전략을 설계함.
Fig. 4는 이 과정과 탐지된 애매한 샘플을 보여줌.
처음에는 FSD로 FoundationStereo 초기 버전을 학습하고, 이 모델을 FSD에 대해 평가함.
이때 BP-2 (Sec. 4.2)가 60% 이상인 샘플은 애매한 샘플로 간주하고 새로운 샘플로 대체함.
이후 학습과 self-curation을 번갈아가며 진행하여, FSD와 FoundationStereo를 두 번 반복하여 업데이트함.
4. Experiments
4.1. Implementation Details
FoundationStereo는 PyTorch로 구현됨.
학습에는 제안한 FSD와 함께 Scene Flow [43], Sintel [6], CREStereo [34], FallingThings [61], InStereo2K [2], Virtual KITTI 2 [7]로 구성된 혼합 dataset을 사용함.
학습은 AdamW optimizer [39]를 사용해 총 20만 step 동안 수행되며, batch size 128을 32개의 NVIDIA A100 GPU에 균등 분산함.
학습률은 초기값 1e-4에서 시작해 전체 학습 과정의 80% 지점에서 0.1배로 감소함.
이미지는 네트워크에 입력되기 전에 320×736으로 무작위로 crop됨.
[36]과 유사한 data augmentation이 적용됨.
학습 시 GRU 업데이트는 22회 수행됨.
이후 언급이 없는 한, zero-shot inference에는 동일한 foundation model을 사용하며, refinement는 32회, 최대 disparity는 416으로 설정함.
4.2. Benchmark Datasets and Metric
Datasets.
총 5개의 공개 dataset에서 성능을 평가함:
- Scene Flow [43]: FlyingThings3D, Driving, Monkaa의 3개 subset을 포함한 synthetic dataset
- Middlebury [51]: 구조화된 빛으로 측정된 고정밀 ground-truth disparity가 포함된 실내 stereo 이미지 쌍
- (별도 언급이 없으면 half resolution과 non-occluded 영역에서 평가)
- ETH3D [52]: 실내외를 포함한 grayscale stereo 이미지 쌍
- KITTI 2012 [20], KITTI 2015 [45]: LIDAR 센서로부터 유도된 sparse disparity ground-truth가 있는 실제 주행 장면
Metrics.
- EPE (End-Point Error): 픽셀 단위 평균 disparity 오차
- BP-X (Bad Pixel-X): disparity 오차가 X 픽셀보다 큰 픽셀의 비율
- D1: 오차가 3픽셀 이상이면서 ground-truth의 5%를 초과하는 픽셀 비율
4.3. Zero-Shot Generalization Comparison
Benchmark Evaluation.
Table 2는 4개의 공개 real-world dataset에서의 zero-shot generalization 성능 비교 결과를 정량적으로 보여줌.
우리 방법은 Scene Flow만으로 학습했음에도, 모든 dataset에서 기존 방법들을 지속적으로 능가함.
이는 vision foundation model에서 얻은 rich monocular prior를 효과적으로 적응시킨 덕분임.
실제 활용을 고려하여, 각 방법은 target domain을 제외한 모든 사용 가능한 dataset에서 학습하도록 허용함.
이는 실용적인 zero-shot 추론 상황에 적합한 평가 조건임.
In-the-Wild Generalization.
혼합 dataset으로 학습된 checkpoint를 공개한 최신 방법들과 비교함. 이는 실제 환경(in-the-wild 이미지)에 대한 zero-shot 적용을 모사함.
비교 대상:
- CroCo v2 [68]
- CREStereo [34]
- IGEV [71]
- Selective-IGEV [67]
각 방법의 공개된 checkpoint 중 가장 성능이 좋은 것을 선택함.
해당 방법들은 real-world benchmark dataset 4개 [20, 45, 51, 52]를 학습에 사용하였으나, 우리의 고정된 foundation model은 이들 dataset을 사용하지 않음.
Fig. 5는 DROID [31] dataset의 로봇 장면, 사용자 수집 실내/실외 이미지 등 다양한 시나리오에서의 정성적 비교를 보여줌.

4.4. In-Domain Comparison
Scene Flow 평가 (Tab. 3)
공식적인 train/test 분할 기준을 동일하게 사용하여 비교함.
우리의 FoundationStereo는 EPE를 0.41에서 0.33으로 개선하며, 기존 방법들을 큰 차이로 능가함.
in-domain 학습이 이 연구의 초점은 아니지만, 모델 설계의 효율성을 반영함.

ETH3D leaderboard 평가 (Tab. 4)
두 가지 설정으로 평가함.
- fine-tuning 사용:학습률 및 augmentation 설정은 동일하게 유지함.이는 in-domain fine-tuning이 필요한 경우, foundation model의 전이 가능성이 매우 크다는 것을 의미함.
- 그 결과, 이전 최고 방법 대비 오류율을 절반 이하로 줄이고 leaderboard 1위에 오름.
- 기본 학습 dataset(Sec. 4.1)과 ETH3D 학습 세트를 혼합해 5만 step 추가 학습.
- zero-shot 사용:놀랍게도, 우리의 foundation model은 zero-shot inference로도 in-domain 학습된 선두 방법들과 동일하거나 더 나은 성능을 보여줌.
- ETH3D 데이터 없이도 평가함.
추가로, fine-tuned 모델은 Middlebury leaderboard에서도 1위를 차지함.
세부 사항은 appendix에 설명되어 있음.

4.5. Ablation Study
모델과 dataset에 대한 다양한 설계 선택지를 분석함.
별도 언급이 없는 한, 실험은 FSD의 무작위 subsample (10만개) 버전에서 수행하여 실험 규모를 조절함.
Middlebury dataset은 고품질 ground-truth를 제공하므로 zero-shot generalization을 평가하기 위해 학습 세트에서 결과를 평가함.
본 연구의 초점은 strong generalization을 가진 stereo matching foundation model 구축이므로, 더 나은 성능을 추구할 때 모델 크기를 의도적으로 제한하지 않음.
STA Design Choices.
Tab. 5에서 보이듯, 먼저 rich monocular prior를 적용하기 위해 다양한 vision foundation model을 비교함.
비교 대상에는 DepthAnythingV2 [79]의 다양한 크기 버전과 DINOv2-Large [46]가 포함됨.
이전 연구에서 DINOv2는 correspondence matching에서 유망한 결과를 보였지만 [19], stereo matching task에서는 DepthAnythingV2만큼 효과적이지 않음.
이는 DINOv2가 stereo task에 덜 특화되어 있고, 고해상도 pixel-level 정합을 수행하기엔 resolution이 부족하기 때문일 수 있음.
다음으로 Fig. 3에 제시된 다양한 설계 방식들 중 (a), (b), (c)를 비교함.
단순한 구조임에도 (c)가 다른 방식들을 현저히 능가함.
이유는 (c) 방식에서 final output head 직전의 feature가 고해상도 및 정밀한 semantic/geometric prior를 잘 보존하여 이후 cost volume 구성과 filtering에 적합하기 때문으로 추정됨.
또한, adapted ViT 모델을 freeze할지 여부도 실험함.
예상대로 ViT를 unfreeze하면 pretrained monocular prior가 망가져 성능이 저하됨.

AHCF Design Choices.
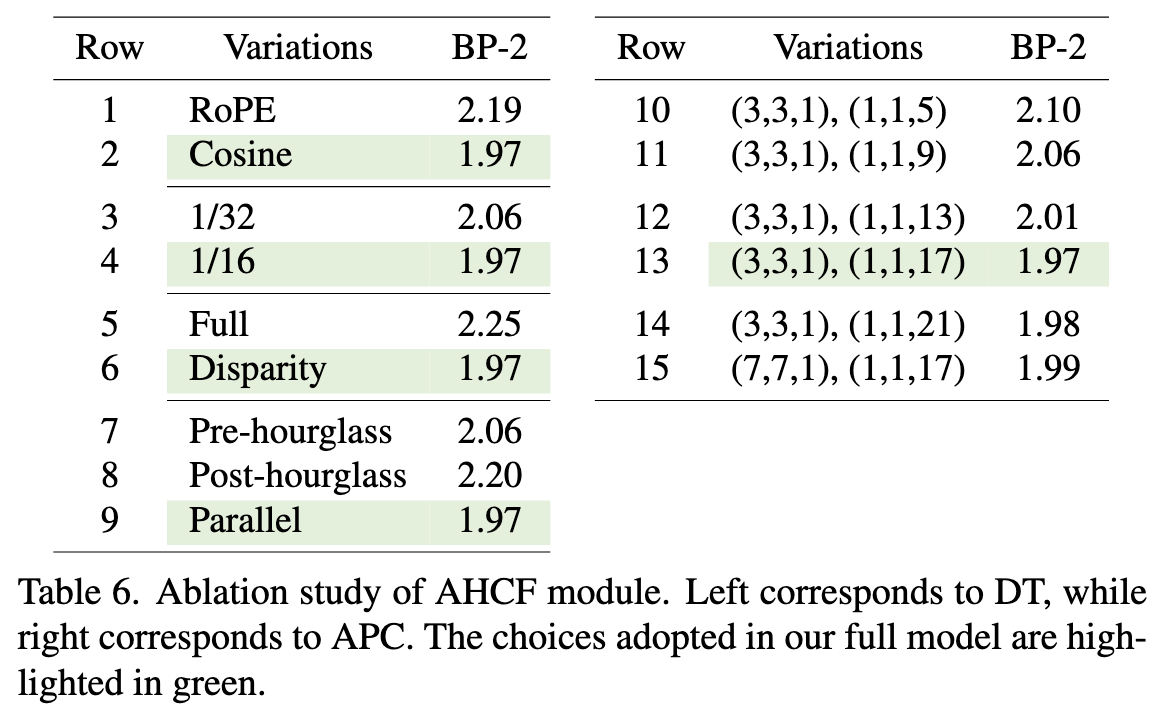
Tab. 6에서 DT 모듈에 대한 ablation 실험을 수행함.
- row 1–2: position embedding 방식 (cosine vs RoPE)
- row 3–4: transformer를 적용할 feature scale
- row 5–6: full cost volume vs disparity 차원에만 transformer 적용
- row 7–9: DT 모듈을 hourglass 네트워크 내 어디에 배치할지
특히, RoPE [55]는 token 간의 상대적 거리를 인코딩하여 다양한 sequence length에 더 잘 적응함.
하지만 4D cost volume에서는 disparity 크기가 고정되어 있으므로 cosine position embedding보다 성능이 떨어짐.
이론적으로 full volume attention은 더 넓은 receptive field를 제공하지만, 실제로는 disparity 차원에만 attention을 적용하는 것이 더 효과적임.
이는 4D cost volume의 공간이 지나치게 크기 때문에 attention 계산이 비효율적이고, disparity 차원만 고려해도 충분한 context를 얻을 수 있기 때문임.
다음으로, APC의 kernel size에 대한 비교(row 10–15)를 수행함.
각 괄호의 마지막 숫자는 disparity 차원에 해당함.
실험 결과, disparity 방향의 kernel 크기를 키울수록 성능이 향상되며, 약 17에서 포화됨.
Effects of Proposed Modules.
정량적인 효과는 Tab. 7 (left)에 제시됨.
- STA는 rich monocular prior를 활용하여 real image의 ambiguous 영역에서 generalization 성능을 향상시킴.
- DT와 APC는 cost volume feature를 공간 및 disparity 차원에서 효과적으로 집계함.
- 이는 disparity 초기화와 이후 GRU 업데이트 시 lookup에 필요한 context 형성을 돕는 역할을 함.
Fig. 3은 이러한 효과를 시각적으로 보여줌.

Effects of FoundationStereo Dataset.
Sec. 4.1에서 설명한 foundation model 학습 시, 기존 공개 dataset과 함께 FSD를 포함할지 여부에 대해 실험함.
결과는 Tab. 7 (right)에 제시됨.
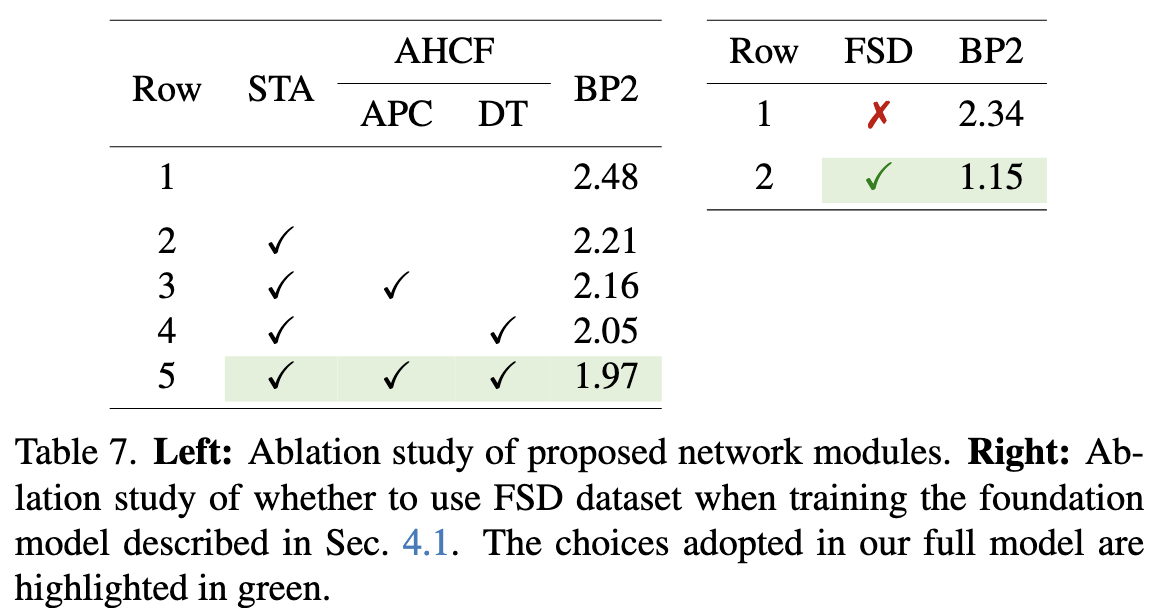
5. Conclusion
우리는 fine-tuning 없이도 다양한 도메인에서 강력한 zero-shot generalization을 달성하는 stereo depth estimation용 foundation model인 FoundationStereo를 소개함.
이러한 foundation model은 실용적인 응용에서 stereo estimation 모델의 보다 광범위한 활용을 촉진할 수 있을 것이라 기대함.
뛰어난 일반화 성능에도 불구하고, 본 모델은 몇 가지 limitations를 가짐.
- 첫째, 현재 모델은 효율성efficiency 측면에서 optimize되지 않았으며, NVIDIA A100 GPU에서 375×1242 이미지 크기 기준 0.7초의 추론 시간이 소요됨.
Future work에서는 다른 vision foundation model에 적용된 distillation 및 pruning 기법 [13, 87]을 적용해 보는 것이 가능함. - 둘째, 우리가 구축한 FSD dataset에는 투명 객체transparent objects의 종류가 제한적임.
학습 시 완전히 투명한 객체의 더 다양한 예시를 augmenting추가함으로써, 모델의 robustness를 더욱 향상시킬 수 있음.