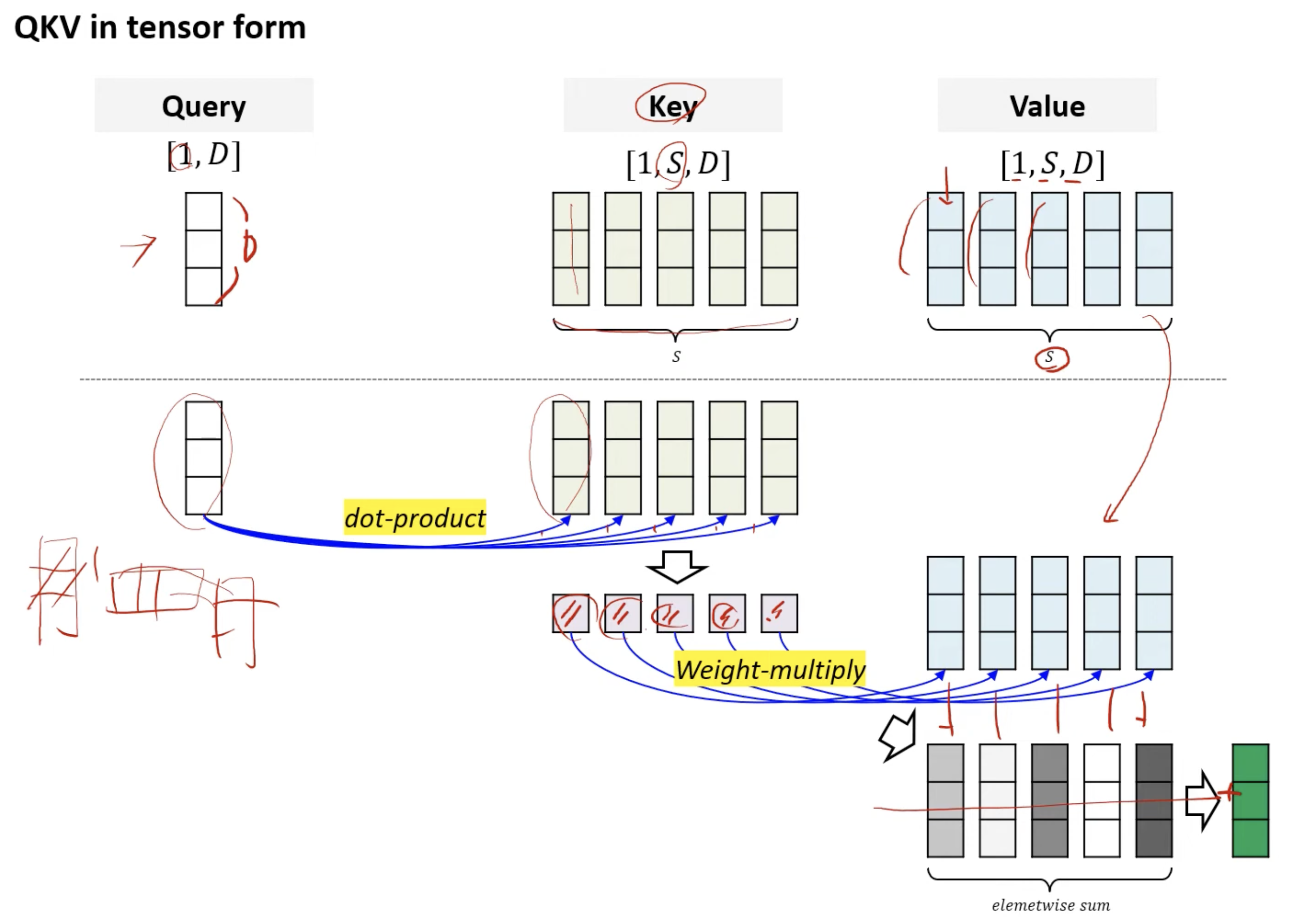
Self Attention문장 내부에서 자기자신과 Cross AttentionCross-Attention은 Transformer 모델에서 디코더가 인코더의 출력을 참조하여 정보를 얻는 메커니즘입니다. 이는 디코더가 현재 생성 중인 출력과 관련된 입력의 부분에 집중할 수 있게 도와줍니다. 예를 들어, 기계 번역에서 영어 문장을 힌디어로 번역할 때, 디코더는 이미 생성된 단어들과 입력 문장의 관련 부분을 동시에 고려하여 다음 단어를 생성합니다.입력 준비:두 개의 입력 시퀀스(예: 이미지 패치 시퀀스와 텍스트 시퀀스)를 준비합니다.Query, Key, Value 생성:디코더의 출력에서 Query를 생성하고, 인코더의 출력에서 Key와 Value를 생성합니다.GeeksforGeeksAttention 계산:..